
Automatic Image Captions
The following post tries to mimic the following idea by google AI LINK and also takes a lot of tips from the final project of the Deep Learning course from the Advanced Machine Learning course on Coursera.
The full script for the project is available in a jupyter notebook here. You may have trouble opening it in github for some reason. I suggest you download it or use the nbViewer here.
Results at the end of this blog post.
Idea
This experiment uses the common objects in context dataset from 2017. We have around 100K images for train and 5K Validation images. For each of those, humans have given some captions (5 captions per images). Here is an example:

The task is to make a machine learning algorithm that gets as an input the image and can generate a caption for that image.
Neural Network Architecture
Obviously, for such an experimental task many advanced approaches are possible. The one I try here is pretty simple:
- First, use a pretrained ImageNet algorithm to get encodings out of its final layer for an image.
- Use that encoding as an initial state for a RNN model (here LSTM) that generates the caption.
It’s a standard encoder-decoder architecture. One network encodes an object and the other network is trained to decode that object.
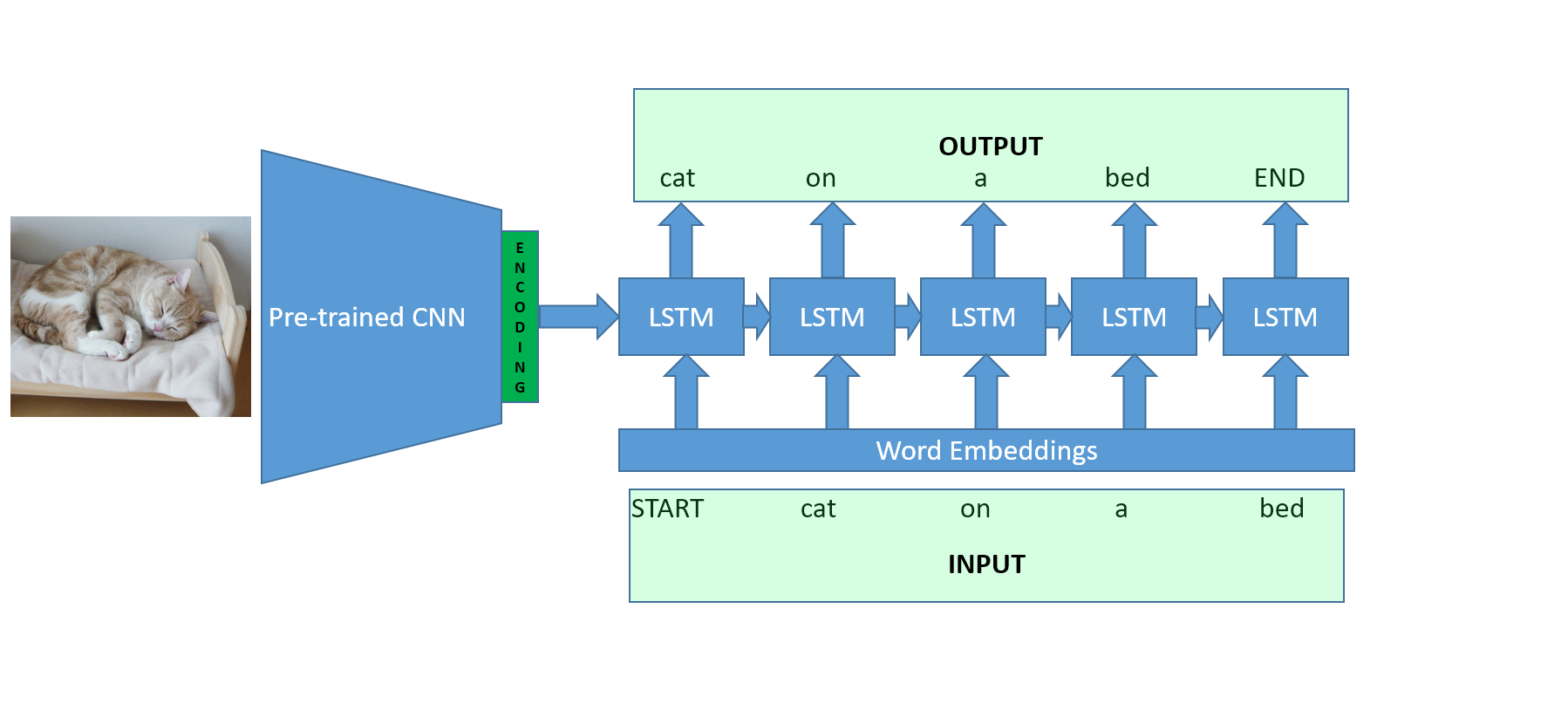
CNN Encoder
For the encoder part I use the ImageNet InceptionV3 model available in Keras:
preprocessing = tf.keras.applications.inception_v3.preprocess_input
model = tf.keras.applications.InceptionV3(include_top=False) #I use inception
model = tf.keras.models.Model(model.inputs, tf.keras.layers.GlobalAveragePooling2D()(model.output))
Each image out of the Zipfile is also centered, croped and resized to what that model needs (299x299 pixels).
img = bytearray(zf.read(f)) #raw bytes
img = cv2.imdecode(np.array(img),1) #this returns an image in BGR format
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) #Convert it to RGB (helps displays)
#The inception model requires square images so we must first crop it to a centered square
h,w,_ = img.shape
if h > w:
d = h - w #Need to crop the height
img = img[d-d//2:h-d//2,:,:]
else:
d = w - h #Need to crop width
img = img[:,d-d//2:w-d//2,:]
#Need to be resized for inception
img = cv2.resize(img, (299,299)).astype("float32") # resize for our model
Once the images are preprocessed they are predicted in batch by the CNN encoder and we get a 2048 size vector for each images. This is in essence a learned numeric representation of the image by a neural network that we will feed to another. All this is then stored in a pretrained matrix which will be used as inputs for each batch of example during training.
LSTM Decoder
For the decoder, a similar technique to machine translation is used. The caption is used both as an input and an output. In a single batch, all captions have to be of the same length so they are padded to match the longest caption with 0s. Finally, a START and END token are added to each sentences to make the model understand what is the beginning and end of a caption.
When the caption is used as an input, the caption starts at the START token until the last word. The purpose is at each word to predict the next word (generative model). Therefore, from the START word and the image the algorithm must try to output the first word of the caption. With the real first word, the second word etc. As a result the output starts at the first word and ends at the END keyword. The model is then trained to minimize the error at each prediction step.
tf.reset_default_graph()
tf.set_random_seed(32)
sess = tf.InteractiveSession()
#Image encodding input
img_encoding = tf.placeholder('float32',[None,2048]) #Image encoding size is 2048
#caption input/output (since the model is generative caption are both an input and an output)
captions = tf.placeholder('int32',[None,None])
image_to_lstm = tf.keras.layers.Dense(300,input_shape=(None,2048),activation='elu')
h0 = image_to_lstm(img_encoding) #Use 300 units LSTM. Therefore initial state is 300 size vector
c0 = h0 #Memory and hidden initial states at same value
#Caption as input (all but the END token)
embed_layer = tf.keras.layers.Embedding(len(vocab),150)
caption_embedding = embed_layer(captions[:,:-1]) #Often the gain between 200 and 300 is small
#Pass the embeddings in a LSTM
#dynamic rnn builds a RNN layer We initiate the LSTM with the img encodings
#Note: We will have to use it differently for predict. Here we have all the words as inputs to predict the next word at each step
lstm_cell = tf.nn.rnn_cell.LSTMCell(300)
h, _ = tf.nn.dynamic_rnn(lstm_cell,caption_embedding,initial_state=tf.nn.rnn_cell.LSTMStateTuple(c0,h0))
#The output of RNN is [batch, time, rnn_size]
#The logloss however will be calculated across all words of the caption for the batch so we need to unroll the LSTM output
h_flat = tf.reshape(h,(-1,300))
y = tf.reshape(captions[:,1:],[-1]) #same for what we need to predict (everything but the START token)
#Predict word logit
lstm_to_logits = tf.keras.layers.Dense(len(vocab),input_shape=(None,300))
word_logits = lstm_to_logits(h_flat)
#Padding mask (no crossentropy there)
pad_mask = tf.not_equal(y,tf.constant(vocab['PAD']))
cross_ent = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=word_logits) #sparse_softmax puts a softmax directly
cross_ent_masked = tf.boolean_mask(cross_ent,pad_mask)
loss = tf.reduce_mean(cross_ent_masked,axis=0)
Prediction
The model created is a generative one. We don’t have any caption word so from the START token and the image, the model must output the whole sequence when doing predictions. The way it is done is by starting with the START token and then using each output word as the input of the next step. The loop stops whenever the algorithm predicts an END token (or reaches the maximum length).
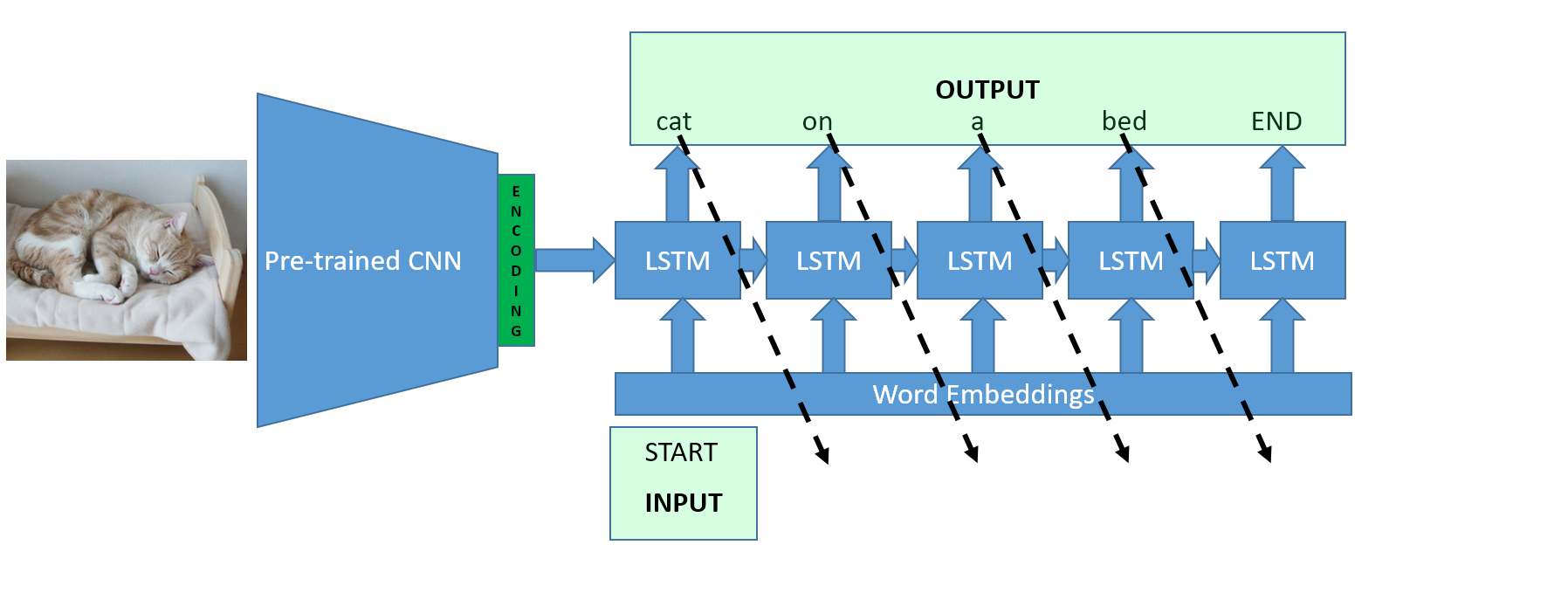
Examples of predictions
Here are a few examples on the validation dataset. Some show great results for this simple technique ! A lot more could be down for both the CNN and RNN parts. The CNN could be trained for that specific task or even use a more modern version, the RNN should probably be combined with a language model instead of learning the language only from captions etc.
Some good examples





Examples with mistakes



Bad Examples


